

Constructing and querying a data model for online harm – Part 2
By Ph.D. Matar Haller, VP Data & AI & Noam Levy, Data Engineer at ActiveFence
Our previous post discussed the pervasiveness of online harm, its multidimensional nature, and why an accurate risk assessment requires analyzing content and its surrounding context. In this post, we will dive into how ActiveFence models our data to enable contextual analysis at scale.
Before we start constructing a data model, we need to understand our problem domain better. Let’s start with a social network company.
The entities that exist on Linkedin are:
- User – a real person’s identity in the platform
- Group – a group of users under the umbrella of the same domain (e.g., Data Engineers Israel)
- Content – a piece of content a user creates
In addition to those three entities, there is a Comment and a Company Page:
- A comment is actually pretty similar to a post – it’s a piece of content a user creates, but it has a context. It’s either a comment to a Post or a comment to another Comment.
- A company Page can be considered a private case of a Group. It’s a group of users under the same domain – the company domain.
Another example is a messaging platform, for example, Telegram. The entities that exist in Telegram are:
- User – A real person’s identity in the platform
- Channel – A chat with one or more users
- Message – A piece of content that a user creates
Here is a simple data model that can capture the entities outlined for both social media and messaging platforms:

The entities for Content and Collection each have fields that describe the content type and the collection type, respectively. Each entity holds fields pointing at the items related to it. For example, a content of-type post should point at its comments, and a user should probably point at their posts. Unfortunately, this naive solution does not work for two primary reasons.
- It is not scalable. If we want to support a new platform with new relationships between its different entities, then to support those new relationships and entities, we will need to extend the schema. For example, Discord has collections (servers consisting of channels). To support collections of collections, we will have to extend our Collection schema with this new type of relationship. Each new platform we want to support will force us to keep extending our schema, while some attributes will make sense for some platforms but won’t make any sense for others.
- Many-to-many relationships – This is a known problem due to the challenge of maintaining these types of relationships. Many-to-many relationships occur in multiple places in the above data model. For example, a piece of Content has a list of its comments (which itself is another piece of content). Comments can also have a list of their comments. To delete a comment, we will have to traverse this contents tree and find the one we want to delete, which is a lot of effort for deleting an item.

We addressed these two challenges by introducing two new elements to our schema:

- A media entity is essentially a thin element that holds a singular media item inline
- Relation entity which captures the relationship between different entities.
The relation entity can also be considered relations from Graph Theory, where the relation type is the predicate, and the subject and the object capture the order of who is related to whom. The relation type is a finite list of human-readable relationships. For example, some valid relation types are: is_comment_of to describe a relationship between a comment and a post (a comment is_a_comment_of a post) and is_created_by to describe a relationship between a post and a user (a post is_created_by a user).

So the content is_created_by the user. Therefore, the content will be the subject of the relation and the user will be the object of the relation. Similar to that, the Content (of type comment) is_comment_of the Content (of type post). Therefore, the comment will be the subject of the relation and the post will be the object of the relation.
With this data model, we can support new relationships on different platforms – all we have to do is extend our relation types list and not our content/collection/user schema. Furthermore, a comment is now an entity in its own right, so deleting it means we have to find the relevant content entity and remove it from our database along with the relation entities where it is the subject or the object.
Let’s take a look at a real-world example.

We have a post here by Donald J. Trump.
Here we persist that data to json lines file:
{“entityType”: “content”, “id”: 1, “contentType”: “post”, “platform”: “LinkedIn”}
{“entityType”: “user”, “id”: 2, “platform”: “LinkedIn”, “name”: “Donald J. Trump”}
{“entityType”: “relation”, “subjectId”: 1, “relationType”: “is_created_by”, “objectId”: 2}
{“entityType”: “media”, “id”: 3, “mediaType”: “text”, “value”: “Even Mexico uses Voter I.D.”}
{“entityType”: “relation”, “subjectId”: 3, “relationType”: “is_body_media_of”, “objectId”: 1}
Now lets see how we can query it with Pyspark:

We are creating a DataFrame of the posts, a DataFrame of the relations that capture a relationship between content to a user (is_created_by), and a DataFrame of users. We need to join the posts with the relations and then join the result with the users to get a full picture of that post and user.
A Data Engineer that wants to query that data has to know for each relation type who is the subject and who is the object to make those join operations correctly. It turns out this is not an easy task because it depends on how we phrase the relationType. So if the relationType is is_created_by then the content is the subject and the user is the object. But what if the relationType was is_creator_of? Now the user is the subject and the content is the object. This arbitrary decision makes the data model difficult to work with.
So we have a great data model, but it is impossible to work with. Modeling the relationships between these items yields a complex connected graph, and to calculate a score that accurately reflects the probability of harm, we need to be able to query and access all of the relations of any given item. We must abstract the complexity of querying a graph-like data model using traditional SQL PySpark queries to provide maximum value to our algorithms.
So we decided to develop a library that does just that.

This piece of code has the same output as the snippet before, but this time the library gets a DataFrame that represents the data we want to collect, some more context, and a list of relation types declaring the context we want to collect.
Under the hood, the library infers for each relation type passed to it which entity is the subject and which entity is the object based on the DataFrame passed to it, reads those DataFrames, and automatically makes the relevant multiple joins for the user. This library enables all data engineers to efficiently and effortlessly query the complex connected graph that models our data.
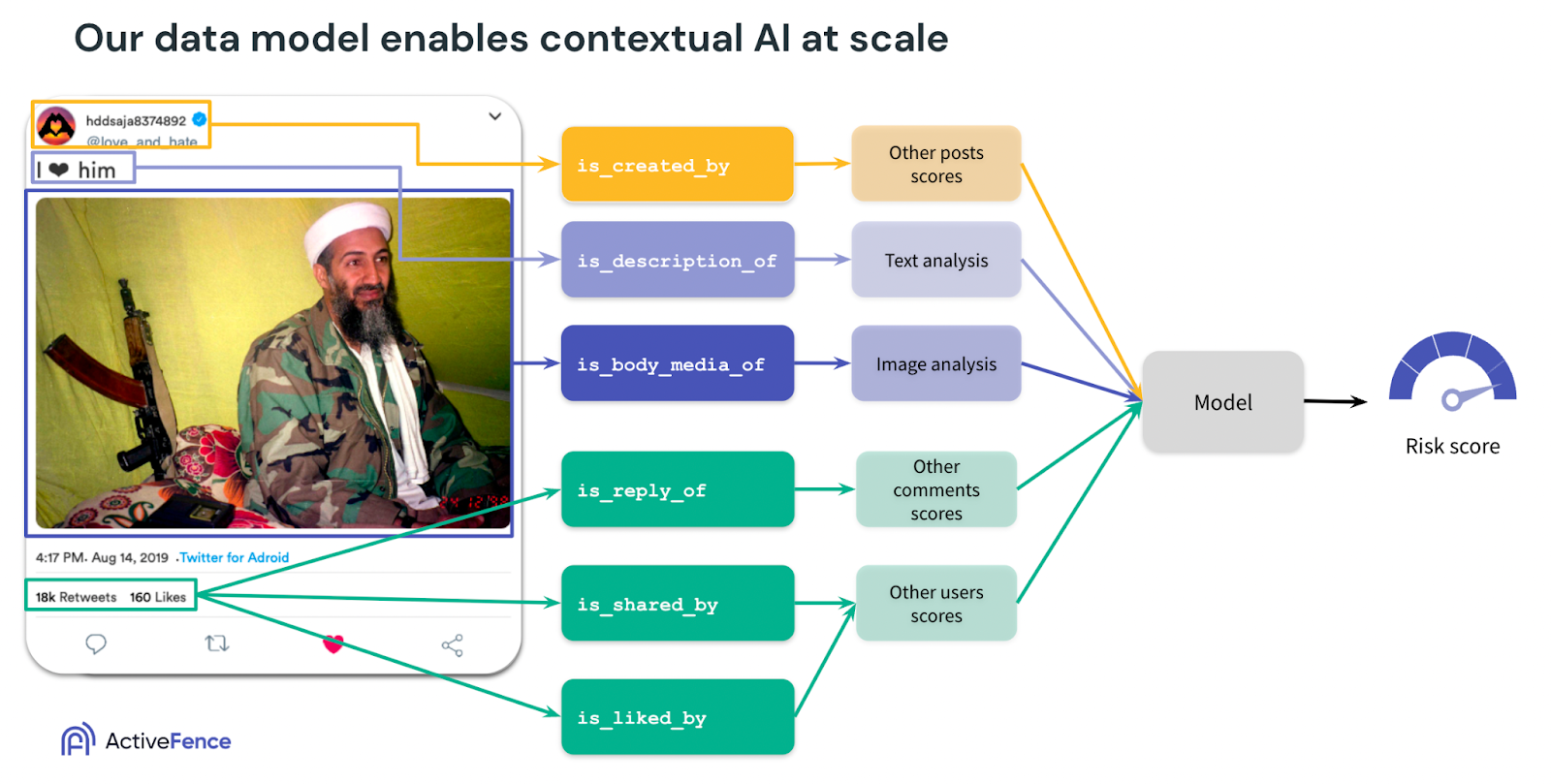
So now that we’ve mapped out the data model and how to query it, let’s see how we can use it to give an accurate assessment of risk. The data model can capture each entity in the post and map it to the relevant fields. In the case below, the Post and the User are connected with the is_created_by relation. This means that our models know that this piece of information reflects the user, and we can run our set of algorithms that are relevant for users, for example, aggregating the risk scores of the other posts by the user. The text in the post is linked to the post with the is_description_of relation, identifying it to our algorithms as text so that our set of text analysis algorithms can run on it. This mapping between data entities and algorithms is infinitely extendable and is what enables us to extract maximum signal from any given post. Finally, the output of these algorithms is fed into our ensemble risk score model, which leverages this plethora of signals to give an accurate assessment of risk that takes into account not only the media but its surrounding context.
At ActiveFence, we aim to make all online interactions safer. To do that, we build models that extract signals from unstructured data and calculate the risk probability. To be able to extract the relevant information from the incoming data, we must have a data model which captures the complexity of online content, including the media, creators, and users that interact with the content with likes, shares, or comments.




