
How Fingerprints Fight Online Evil
By Ziv Kalderon, Engineering Team Lead at ActiveFence
At ActiveFence, we leverage a combination of advanced technology and human expertise to keep users safe from malicious content online.
Malicious content, including hate speech, misinformation, and CSAM, is readily shared on social media platforms. However, using technology, we can make the work of resharing that content more difficult. Once a piece of content is identified as malicious, that identification can be leveraged to detect its duplicates and prevent them from being reshared on the same platform. However, in the case of cross-platform content sharing, that may be a little more challenging.
Indeed, a recent study, found that harmful content – in this case, COVID-19 disinformation, spreads across multiple popular online platforms, in what’s called the multiverse of online hate. The researchers revealed how malicious content exploits pathways between platforms, highlighting the need for social media companies to rethink and adjust their cross-platform content moderation practices.
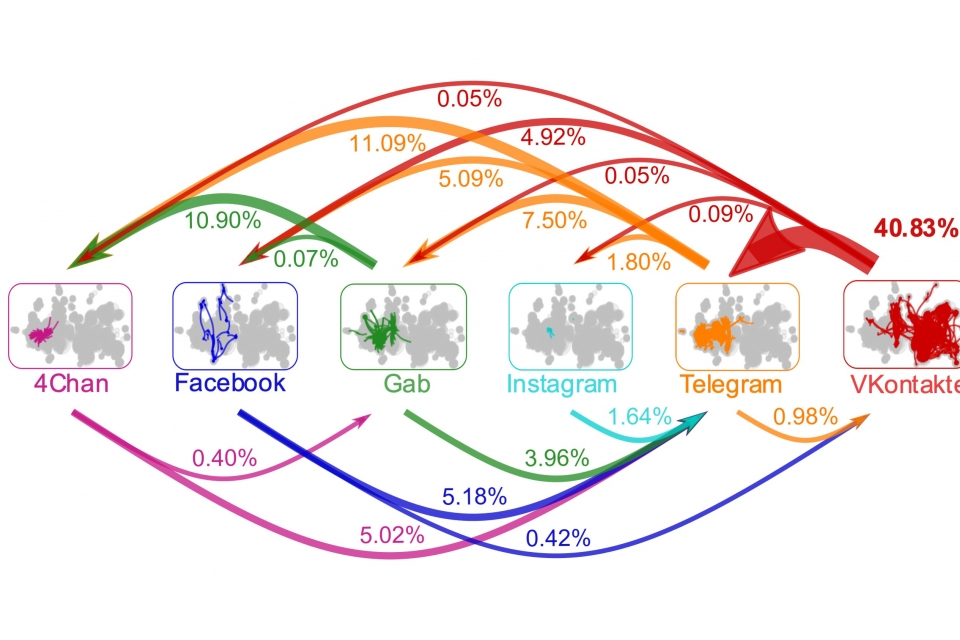
A map of the online hate multiverse. Malicious COVID-19 content exploits the pathways between social media platforms to spread online. (Source, Credit: Neil Johnson)
Hash Databases
Perceptual Hashes are digital signatures of a file. They are unique numerical representations of the original content and can’t be reverse-engineered to recreate the item.
In an ideal world, at least for moderators, every file would have a few unique signatures, based on the common hash algorithms to represent it. However, signatures such as MD5, SHA-1, SHA-256, SSDEEP, and TLSH, which are useful for detecting exact copies of a file, are limited in that they require an exact match of contents, file type, resolution, aspect ratio, and more. This limitation means that hashes aren’t enough for cross-platform content detection.
To illustrate the shortcomings of hash databases, let’s suppose we have a library that contains the hashes of harmful videos, audio files, books, PDFs, and images. A platform seeking to detect harmful content using this library would need to compare the hash of any new content item to the signatures in the library. If the file matches an existing hash, it is malicious. However, a hash database match requires an exact match of contents, file type, resolution, aspect ratio, and more. Consider a file that was posted on that platform after it was shared on a direct-messaging platform that decreases its resolution, or a file-sharing platform that added a watermark – each of these changes would change the file’s hash, making it impossible to compare to the original file using a simple hash.
The Solution: Digital Fingerprinting
A different approach is required to detect media duplicates while ignoring basic file alterations like watermarking, cropping, rotations, resolution changes, and more. A combination of algorithms and technologies like pHash, PhotoDNA, PDQ, and TMK has been developed by some of the world’s leading engineers for this exact purpose. Instead of focusing on an exact match, they capture perceptual matches by generating a unique fingerprint for media files.
Fingerprinting essentially involves using a combination of algorithms to map individual identifiers of the file: its components, size, resolution, and quality, to name a few. Together, these make up a file’s unique fingerprint, which can then be compared to new media files to assess the “level of similarity” rather than a yes/no hash match. The ability of fingerprinting technology to compare near-identical images gives it a unique edge in cross-platform content moderation, as it isn’t challenged by the inevitable changes applied to media as it is shared across platforms.

Similarly to hashes, fingerprints cannot be reverse-engineered to recreate the original file, making them a safe solution for Trust & Safety teams. This advantage also allows us to store the data we need to identify content, without storing the original media – which may include illegal content like child exploitative media.
Storing and Matching Data
Digital fingerprinting technology powers ActiveFence’s ability to conduct intelligence-driven automated detection.
The intelligence collected by our vast team of domain experts – which includes abuse trends, media, and data shared on the clear and dark web, is validated as harmful and automatically fingerprinted. These fingerprints are safely stored in our database alongside the item’s metadata. Items uploaded to our partners’ platforms are then analyzed by comparing their digital fingerprints to those stored in our databases of malicious content.
Since we want to identify files that are near-matches, not necessarily exact duplicates of previously identified malicious content (thereby maintaining high recall without trading too much precision), we query the database and return all matches that are below a threshold distance from our incoming fingerprint.
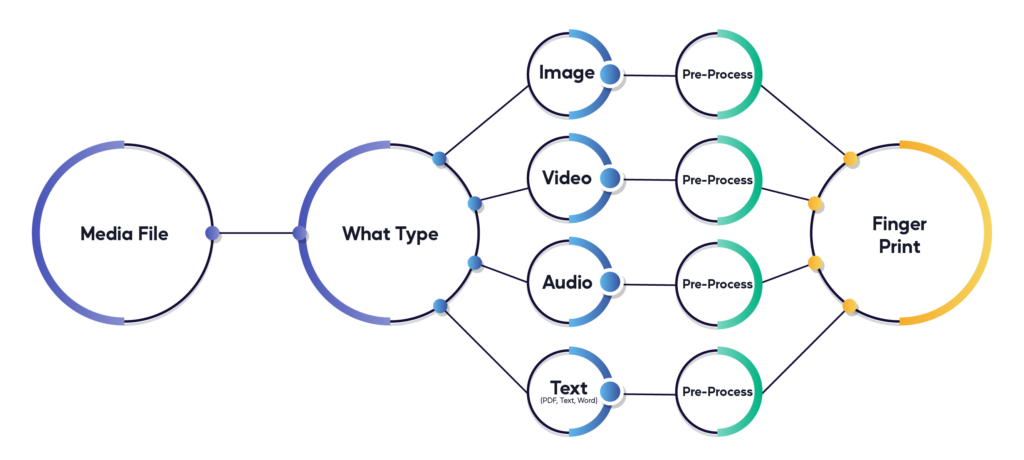
However, while useful, fingerprints are not the only indicator we use to determine whether or not a piece of content is malicious Numerous algorithms and models work to extract signals from unstructured content (images, videos, text, audio) in order to help our AI system determine the probability that content is malicious. That said, we find that items that are detected as duplicates using our hash comparison, end up being confirmed as malicious more than 99% of the time, thus making this system, and our proprietary data assets, core components in making the internet a safer place.
Conclusion
Fingerprints of media files are a powerful way to detect duplicates of harmful content and are a critical component in stopping the online spreading of malicious content. At ActiveFence, we are constantly updating and maintaining our proprietary data assets in order to be able to detect duplicates and stop their proliferation. Leveraging multiple cutting-edge technologies and massive amounts of data makes ActiveFence the leader in the detection of online harm.




