
How did we get to a deep learning model for symbol recognition with a small amount of labeled information?
By Iyar Zaks, Data Scientist at ActiveFence
Online platforms with user-generated content, whether it is comments, posts, or videos, have petabytes of data uploaded at a rapid rate. Within this data hides offensive content and malicious behavior, which encompasses a variety of media types (such as text, image, video, and audio). Detecting online harm requires advanced expertise in the subject domain and AI to identify the rare malicious behaviors hiding among the data.
One way to identify organized malicious behavior online is to identify symbols or logos of organizations that distribute offensive content repeatedly. These organizations, which use online platforms to spread their messages to the general public, often do not promote content using their organization’s name because then it is too easy to identify them. These bad actors are keenly aware that content undergoes some level of moderation and filtering. Yet it is also essential for them that the harmful content is identified with them to receive credit for its distribution and to increase the sense of belonging among their followers. So these organizations and bad actors will provide clues identifying them in the content they share, often in the form of some identification mark as part of the shared visual media (video or image).


With this insight, we built an automatic model for finding these symbols and logos in uploaded visual content to use as a signal to be sent to downstream models. After a review of the solutions that solved similar problems in commercial contexts (recognition of logos of fashion companies, for example), we decided to test training a deep learning model for object recognition named YOLO – You Only Look Once.
What is YOLO, and how can you use it?
You Only Look Once (YOLO) is a family of several versions of deep neural networks sharing a common architecture. The networks receive an image as input and provide an output of the objects detected in the image, including details about the areas where they were detected in the image in the form of bounding boxes. The object detection systems based on these networks are currently considered state-of-the-art and the best for real-time object detection.
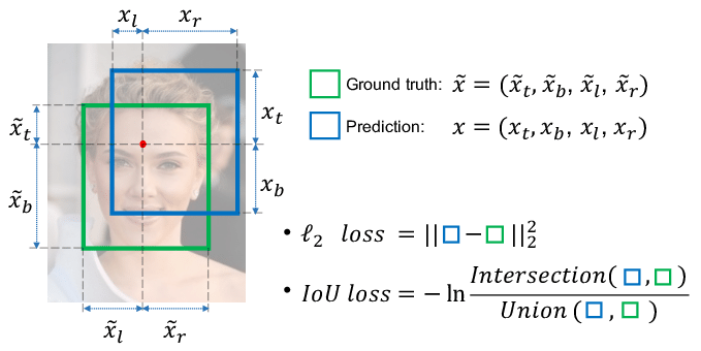
Like other neural networks, YOLO is trained with the help of manually labeled data, with a loss function consisting of incorrect identification of the object and inaccurate bounding box location and size. Thus, throughout the training, the network learns from its mistakes to be able to correctly classify the objects and insert the bounding boxes accurately in the image.
The network is most frequently used as-is for inference without specific training, making it relatively simple and fast to find objects in an efficient, quick manner. In our case, using the network is insufficient since it has been trained to find common objects such as people, vehicles, and animals – not symbols of terrorist organizations or hate groups. Therefore, we chose to train the network to find the specific objects that are relevant to our use case.
How do you find labeled information for training?
After realizing that we wanted to train the YOLO network to identify new objects (symbols that can indicate offensive content), we needed to obtain images labeled in a way that aligns with the YOLO training format. Training a computer vision network requires many labeled images, a difficult challenge in any field and application, and even more so in a field where the images are difficult to find since the organizations rarely advertise themselves publicly. In addition to familiar symbols that can be easily collected, such as swastikas, there are many logos belonging to esoteric organizations with examples that are not easily accessible on the open web.
There are two options for obtaining the required amount of labeled training data. The first is to collect photos and videos from different sources and use a dedicated platform and dedicated annotators to label and draw bounding boxes. This requires manual work, including collection from difficult-to-access sources and high-quality annotation and labeling. The second option is to generate suitable synthetic training images. In the case of synthetic data, there is no need for additional labeling or drawing bounding boxes because we predetermine both the logo and its location when generating the image. The challenge with synthetic data is to create images that simulate the real world well enough for the model to learn from them.
There are two types of symbols or logos for which we want to create synthetic data. The first type of images, which we termed two-dimensional symbols, exist on a flat plane and are pasted onto the image or video (e.g., a CNN logo). For these types of logos, it is relatively easy to create reliable images that mimic reality and that the model can learn from. The second type, which we termed three-dimensional symbols, appears as part of the image itself, for example, a football team logo that can appear on team flags and team uniforms. Creating realistic images with such symbols requires more complex solutions than simply pasting on existing images, so we utilize more modern methods, specifically diffusion models.
2D example:

3D example:

Training, augmentations, and hyperparameter selection
When training a deep network, especially one for computer vision tasks, there are several considerations. The first is the hardware on which we perform the training. The second consideration is the possibility of performing augmentations to increase the diversity of the existing data and prevent overfitting. Overfitting means that the model cannot generalize to new incoming data because it was trained on data that does not reflect the real world. The third consideration is hyperparameter selection. These are parameters that are not learned but are selected in advance and can strongly affect the network’s performance.
The open-source library that enables training the YOLO network makes training several GPU cores in parallel very convenient and accessible, significantly speeding up network training. The library also enables augmentations to be performed automatically as part of the training process, which means the developer does not need to perform augmentations separately in a pre-training process. The library also offers a genetic algorithm tool that enables a smart search for optimal hyperparameters, thereby freeing the developer from having to search for hyperparameters separately.
The images below contain ISIS and Hezbollah logos. They exemplify the challenges inherent in identifying logos or symbols that are part of real-world scenes, whether in terms of image quality or partially occluded symbols. The green squares on the images indicate bounding boxes where the model detected the object. They also contain the name of the object and the model confidence in the detection.


At the end of the project, we were able to train a model to recognize a large set of diverse malicious symbols and logos with a high level of accuracy. This malicious logo detection model is a core component of ActiveFence’s AI capabilities, which we use to identify harmful content online and protect users and communities.




